The Power Law distribution - and how I couldn't find one
Today I’m going to write about power law distributions. Power laws are very common in statistics, because they model many common phenomena very closely. The following image shows the typical shape of a power-law distribution. A few elements (in green) contain a very large proportion of the area of the curve, and the rest (in yellow) is a very long tail of ‘average-valued’ elements.
As I mentioned, this kind of distribution is observed in many phenomena. Actually, power laws have been observed in physics for a while now, but with the new ubiquity of data on human activities, there is a sort of hype around them. They are popping up everywhere to explain human-related phenomena. For instance the frequencies of words in human languages show a power-law distribution: Aproximately 80% of what we say can be said with only 20% of the words of the English language (e.g. 7% of the words in a book are just “the”). This is true for many human languages!
Another phenomenon that shows power-law behavior is the [amount of friends on Facebook] (http://www.facebook.com/notes/facebook-data-team/anatomy-of-facebook/10150388519243859). Most people have only a few friends, but there is also a significant amount of people in the ‘long tail’. This is, a significant amount of people that have a large amount of friends (more than 500).
The power law typically appears to describe phenomena that are about popularity. Facebook friends, twitter followers, sales of books (a few books account for most of the sales), total grossing of movies, size of cities, number of speakers of languages, distribution of household incomes, level of collaboration on online communities, and countless other phenomena show power law behavior or something very close to it!
With all this excitement about power laws, naturally many researchers have jumped on the power-law train, and made unsustainable claims about their data, for instance Clay Shirky’s Blog In-degree distribution claims. It wasn’t long until someone set out to kill a few birds in a single shot: [Clauset et al looked at 24 distributions] (http://arxiv.org/pdf/0706.1062v2.pdf) that had been claimed to be power laws by other researchers (sucha as word frequency, terrorist attack fatalities, religious sect size, surname frequency, in-degrees per URL, etc.), and found that only one of the 24 was a clear power law. Pretty disappointing huh? Clauset et al were nice enough to provide code for others to test their data for power-law-ness, and the code was later translated to Python too.
Well, I ran into my own dataset that I suspected of being a power law. I found some [data of registered businesses in Mexico] (http://www3.inegi.org.mx/sistemas/descarga/), published by the National Institute of Geography and Statistics (INEGI). Particularly, data of “manufacturing businesses” - which includes bakeries and tortilla makers. I grouped the data by business type, and found that most of the businesses are of very few types (20% of registered manufacturing businesses are tortilla makers!). Here is my data on a log-log scale:
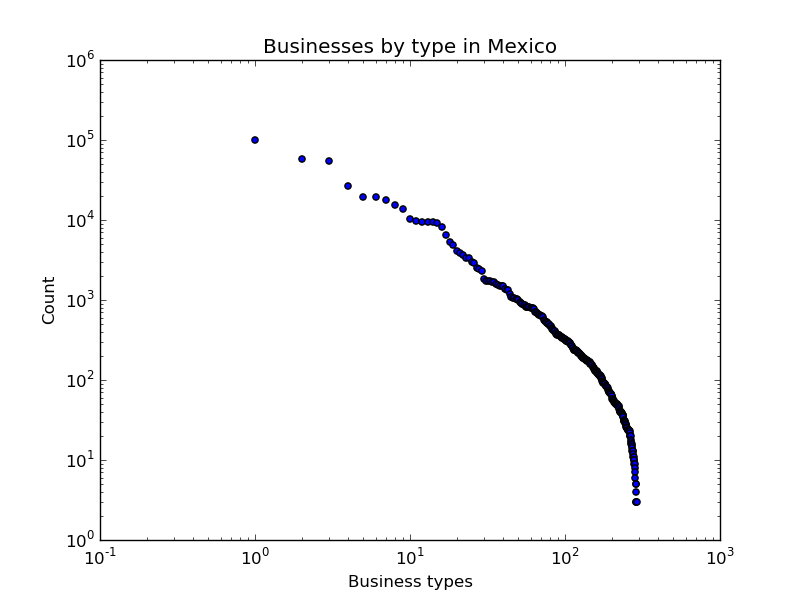
You can see it’s definitely not a straight line, so there is no way it could fit to a power law, right? Well, as it turns out, when researchers fit their data to power laws, they typically do it for a fraction of their data (the tail, or the beginning of it); so upon first imporession it was not entirely certain whether we had a power law in our hands or not - if only for the beginning of the distribution. To test that I used the code from Clauset et al’s paper, which includes a Maximum Likelihood Estimator of the exponent, as well as a Kolmogorov-Smirnov goodnes-of-fit test. Spoler alert: The fit was really bad, and the P value was 1 or something embarrassing.
And that’s the story of how I failed to fit my first power law. The code, which is nothing more than loading the data and applying
plfit, is available on Github for the curious. I’ll be back soon with more on this data,
which I find pretty interesting. I will probably try to fit it to another distribution (Log-Normal?). Until then.